Reducing Loss Recovery Latency with RTO Restart
RTO Restart (RTOR) is an algorithm for managing the TCP and SCTP retransmission timers that provides faster loss recovery when there is a small amount of outstanding data for a connection.
The modification allows the transport to restart its retransmission timer more aggressively in situations where fast retransmit cannot be used. This enables faster loss detection and recovery for connections that are short-lived or application-limited.
The Problem
The standard retransmission timer management algorithm described in RFC6298 recommends that the retransmission timer is restarted when an acknowledgment (ACK) that acknowledges new data is received and there is still outstanding data. The restart is conducted to guarantee that unacknowledged segments will be retransmitted after approximately RTO seconds.
However, by restarting the timer on each incoming ACK, retransmissions are not typically triggered RTO seconds after their previous transmission but rather RTO seconds after the last ACK arrived. The duration of this extra delay depends on several factors but is in most cases approximately one RTT. Hence, in most situations, the time before a retransmission is triggered is equal to “RTO + RTT”.
The extra delay can be significant, especially for applications that use a lower RTOmin than the standard of 1 second and/or in environments with high RTTs, e.g. mobile networks.
The Solution
To enable faster loss recovery for connections unable to use fast retransmit RTOR sets the retransmission timer to “RTO – T” on each incoming ACK, where T is the time elapsed since the earliest outstanding segment was sent. This behaviour ensures retransmission to always occur after exactly RTO seconds.
An implementation can use the following logic to implement RTOR:
When an ACK is received that acknowledges new data:
1) Set T_earliest = 0.
2) If the total number of outstanding and previously unsent
segments is less than an RTOR threshold (rrthresh), set
T_earliest to the time elapsed since the earliest outstanding
segment was sent.
3) Restart the retransmission timer so that it will expire after
(for the current value of RTO):
(a) RTO - T_earliest, if RTO - T_earliest is > 0.
(b) RTO, otherwise.
The Benefits
We have evaluated RTOR in a number of situations, including detailed tail loss scenarios, realistic bursty traffic and web page downloads. All experiments have been conducted with real end-hosts running Linux 3.17 equipped with RTOR. Below we present a small subset of the achieved results. We have also included the recent loss recovery enhancement Tail Loss Probe (TLP) in our experiments, for comparison.
Controlled Tail Loss
For these experiments, a sender transmits 10 segments (one full initial window) to a receiver over an emulated network. The sender and receiver used three combinations of loss recovery mechanisms:
baseline: standard Linux with TLP turned off (net.ipv4.tcp_early_retrans = 2)
RTOR: standard Linux with TLP turned off and RTOR enabled
TLP: standard Linux with TLP turned on (net.ipv4.tcp_early_retrans = 3)
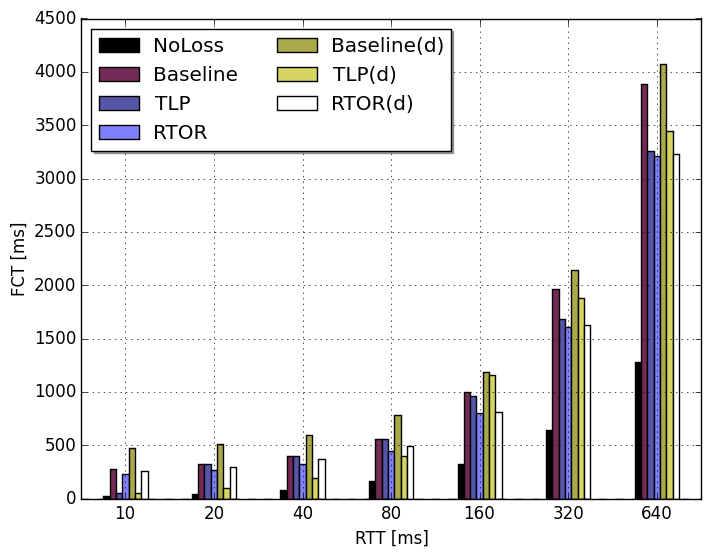
The emulator imposed RTTs (10ms — 640ms) and introduced exact tail drops. To quantify the effect of different loss recovery mechanisms we measured the Flow Completion Time (FCT). Here, we define FCT as the time elapsed from the start of the connection initiation to the successful reception of the last data segment.
The graph below shows the FCTs for all loss recovery combinations with and without the use of delayed ACKs at the receiver. For instance, TLP(d) is TLP with delayed ACKs enabled at the receiver. The FCT in the graph were all achieved when the last packet of a 10-segment flow was dropped by the emulator. As shown in the graph RTOR is able to reduce the FCT with approximately one RTT, as compared with the baseline, for all different RTTs. TLP is also reducing the FCT but not for low RTTs. The reason for this is simply that TLP schedules its PTO timer in a way similar to how the original RTO timer is scheduled, i.e., with an implicit offset. When using delayed ACKs instead of the Linux quickacks the behavior is similar; only for an RTT of 10ms a difference can be seen between TLP and TLP(d). The difference is related to the way TLP sets its Probe TimeOut (PTO) timer. If only a single segment is outstanding the PTO is normally set to a value larger than 200ms to compensate for delayed ACKs. If more than one segment is outstanding, the PTO is set to max(2*SRTT, 10ms). However, if the RTT is very low and the last segment is lost, the delayed ACK from receiving the 9th segment will not arrive at the sender in time to reset the PTO to compensate for delayed ACKs. Instead, the sender’s PTO will expire and the segment will be retransmitted prematurely.
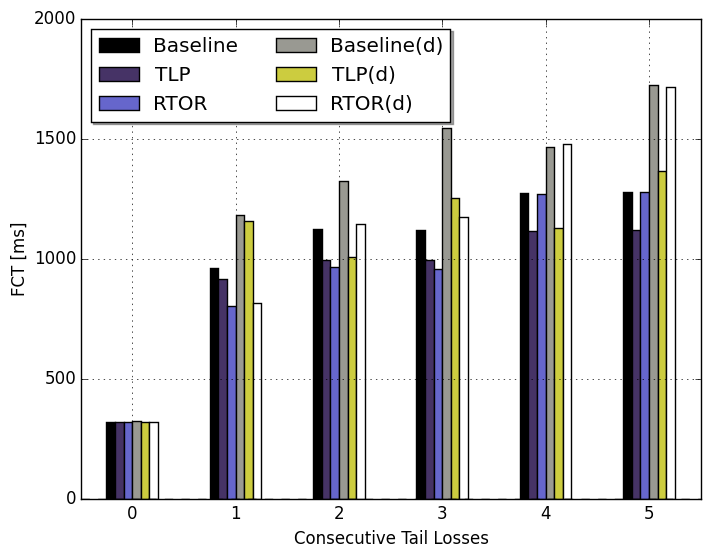
Next, we vary the degree of tail loss between 0 and 5 consecutive losses (counted from the end of the flow) to see what happens when more segments are lost. The RTT used in this particular experiment was set to 80ms. As shown in the graph below, RTOR performs better or roughly the same as TLP when loosing 1-3 segments in the end of a flow. When the degree of tail loss is further increased RTOR is unable to reduce the loss recovery time, while TLP is still reducing the time needed due to its invocation of FACK-based loss recovery
Realistic Tail Loss
In reality loss do not always occur consecutively in the tail, starting with the last packet, but rather anywhere in a flow. Furthermore, RTTs are of course not static. To make things more realistic we used the Tmix traffic generator to create background traffic; this background traffic then introduced both varying RTTs and loss in our measurement traffic. For these experiments, we noted an increase of about 0.04% in spurious retransmissions when using RTOR.
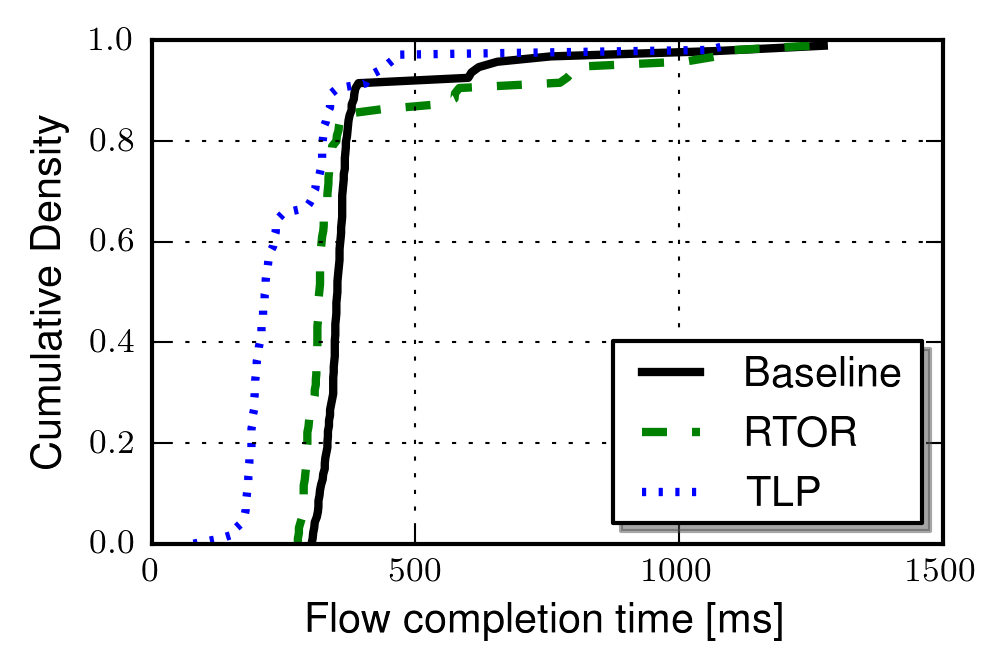
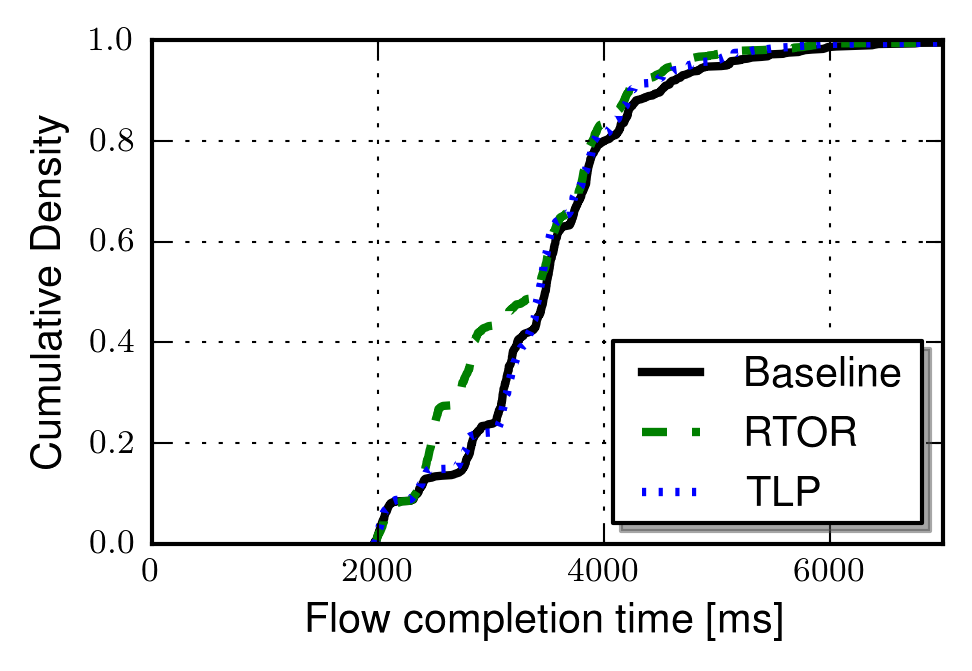
The graph below show FCTs for short 4-segment flows with a base RTT of 10ms. The results clearly show that RTOR saves one RTT as compared to the baseline. It also shows that TLP performs better for 60% of all flows. The reason for TLPs good performance in this region is that several segments in tail are lost for these flows.
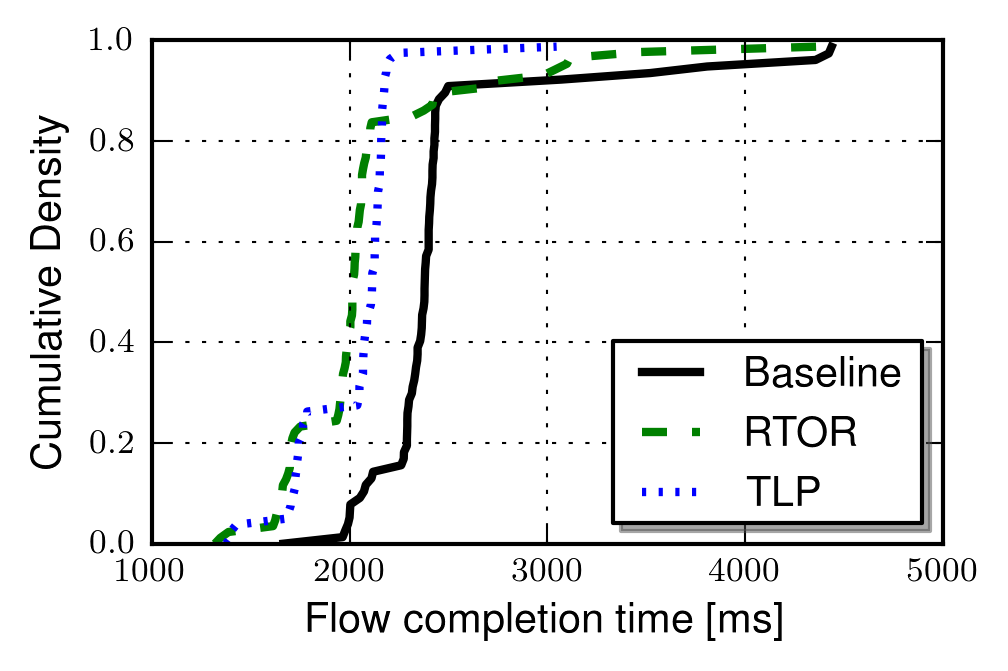
As the RTT increases the loss recovery reductions are, obviously, larger and RTOR performs slightly better than TLP in most cases. This is illustrated by the graph below, were the RTT was approximately 320ms.
When flow sizes increase, however, the relative effect of RTOR decreases; in such scenarios tail losses do not impact the FCT much as the tail is such a small portion of the entire flow. Therefore other mechanisms such as fast retransmit is typically overriding RTOR. This is illustrated by the graph below were each TCP flow consisted of 100 data segments and the RTT approximately 320ms.
Web Page Downloads
To determine the usefulness of using RTOR for real applications we performed a series of web experiments. To perform controlled experiments but still use real web sites we downloaded the sites listed in the Swedish version of the Alexa Top 500 list to a local web server. We then downloaded each site from the web server over an emulated network and measured the completion time of each web object. The download process mimics the common web browser behaviour of first retrieving the HTML document, and then all resources (images, style sheets and javascripts) associated with the document. The resource download was performed using a maximum of six parallel connections per domain. The network conditions were emulated using KauNet and included a range of RTTs (10-160ms). To create realistic segment loss we used a Gilbert-Elliot model to create correlated loss patterns. The average loss probability was approximately 1.5%.
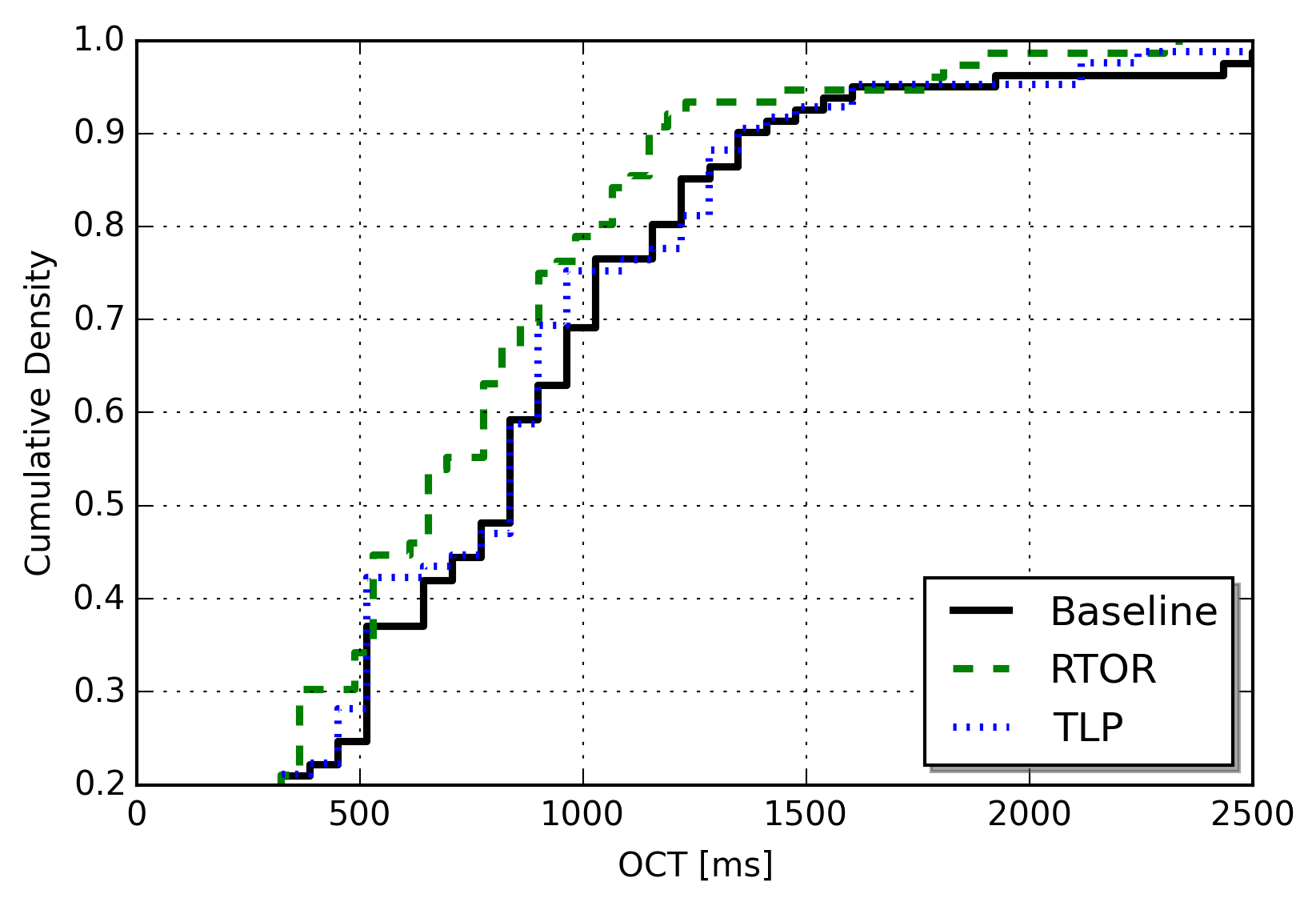
The graphs below contains samples of the results, showing the object completion time (OCT) for all objects in flows where at least one object experience a segment retransmission for one of the last four segments of the object. Our definition of OCT is the time elapsed from the client request to the successful reception of the last data segment. Each graph contains the OCTs for 300 repetitions, for each loss recovery mechanism. The first graph shows the results for a Swedish telephony search engine. This site is very lightweight and contains a total of 12 objects with a mean size of approximately 24 Kbytes. As shown in the CDF, RTOR is able to reduce the OCT considerably compared to the baseline.
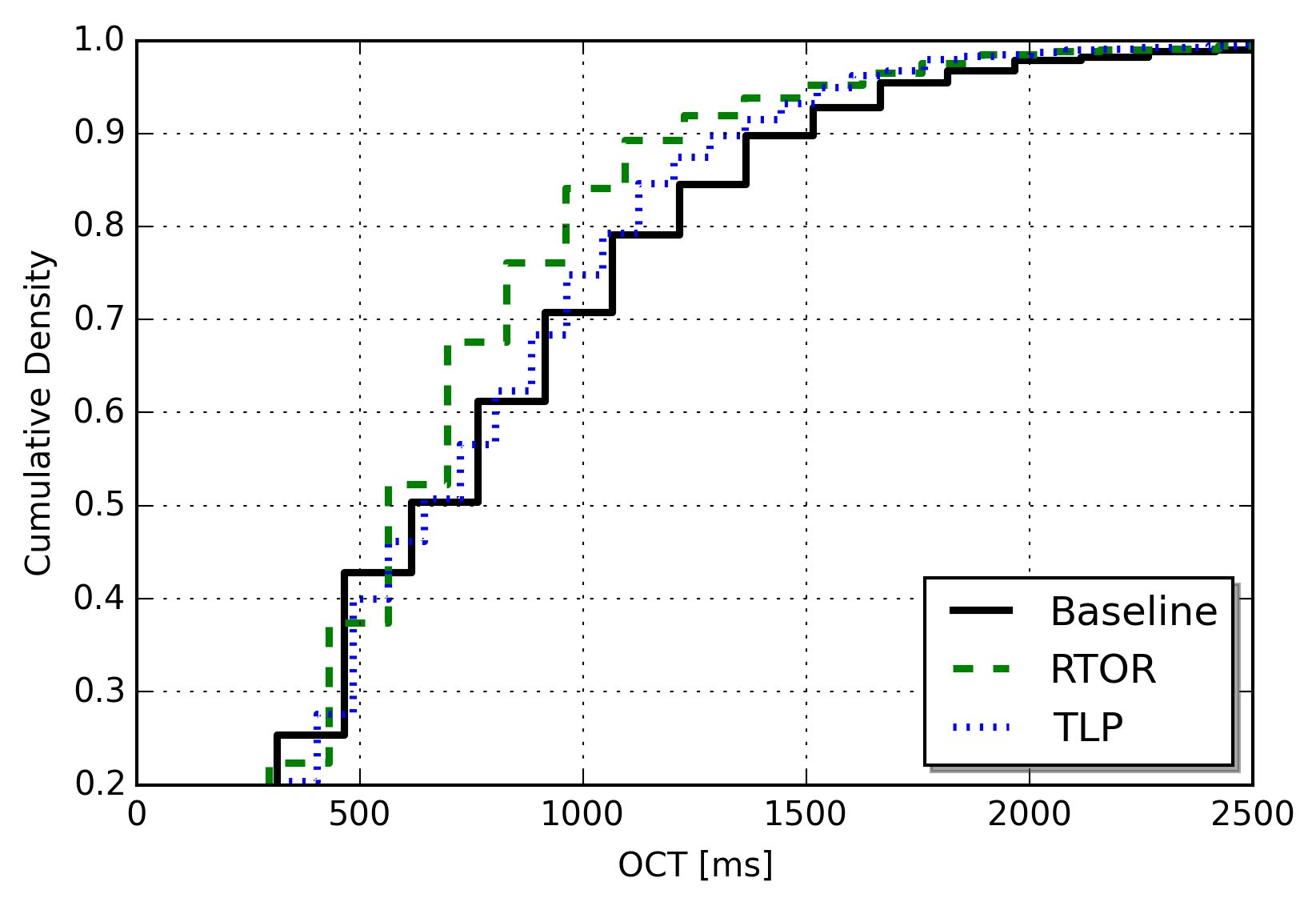
As for the previous experiments, the relative gain of using RTOR is tightly coupled to the specific traffic pattern and all web sites are certainly not the same. Below is the OCTs for a large swedish newspaper where the object size distribution as well as the number of objects are very different from the previous site; a total of 164 objects with a mean size of about 25 Kbytes. This distribution of objects and object sizes lower the relative gain of using RTOR. However, when loss do occur RTOR consistently reduces the OCT with one RTT.
Both RTOR and TLP increase the amount of spurious retransmissions. In total for our webexperiments, the fraction of spurious retransmissions for the different mechanisms:
Baseline: 4.8 x 10^-5
RTOR: 5.9 x 10^-5
TLP: 1.8 x 10^-3
More Stuff
Implementation
The implementation of RTOR can be downloaded from here, in the form of a patch for Linux 4.0-rc4. Please refer to the git documentation on how to apply a patch and a Linux kernel tutorial, e.g. this one, on how to build a custom kernel.
Detailed Description
RTOR Internet-Draft: draft-ietf-tcpm-rtorestart

Thanks for sharing your info. I truly appreciate your efforts and I am waiting for your further post
thanks once again.